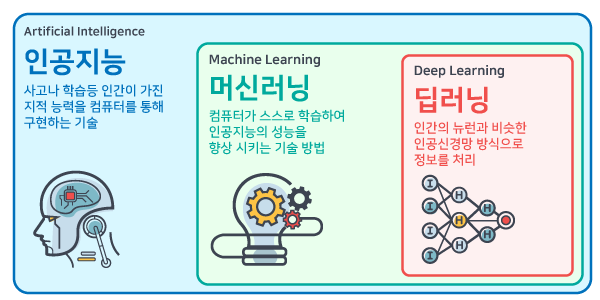
인공지능 (Artificial Intelligence)
사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술
머신러닝(Machine Learning)
규칙을 일일이 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
scikit-learn이 대표적인 라이브러리입니다.
(통계학에서 유래된 머신러닝 알고리즘이 많으며 통계학과 컴퓨터 과학 분야가 상호 작용하며, 발전 중입니다.
대표적인 오픈소스 통계 소프트웨어인 R에는 다양한 머신러닝 알고리즘이 구현되어 있습니다)
딥러닝(Deep learning)
입력층과 출력층 사이에 여러 개의 은닉(Hidden layer)들로 이뤄진 인공신경망을 딥 뉴럴 네트워크(Deep Neural NEtwork) 또는 딥러닝(Deep Learning)이라고
Tensor Flow와 PyTorch가 대표적인 라이브러리입니다.
그렇다면 머신러닝(Machine Learning)과 딥러닝(Deep learning)의 차이는 무엇일까?

특징 추출(Feature extraction) 사람이 개입해서 조정한다면 머신러닝이고,
특징 추출(Feature extraction) 딥러닝 알고리즘 신경망을 통해 조정한다면 딥러닝입니다.

| 머신러닝 (Machin Learning) |
지도학습 (Supervised learning) |
분류 (Classification) | 진단 |
| 영상분류 | |||
| 사기탐지 | |||
| 번호판 인식 | |||
| 회귀(Regression) | 시장 예보 | ||
| 인구증가 예측 | |||
| 날씨 예측 | |||
| 비지도학습 (unsupervised learning) |
군집화(Clustering) | 고객 세분화 | |
| 추천 시스템 | |||
| 목표 마케팅 | |||
| 데이터 마이닝 | |||
| 차원 축소 (Dimensionality redution) |
특징 추출 | ||
| 빅데이터 가시화 | |||
| 강화학습 (Reinforcement learning) | 인공지능 게임 | ||
| 실시간 판단 | |||
| 로봇 내비게이션 | |||
| 학습 업무 | |||
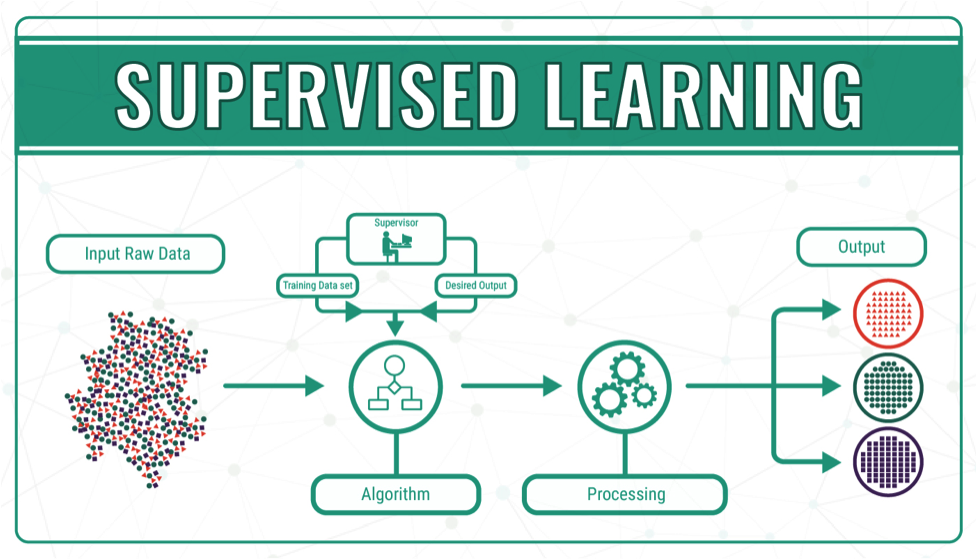
지도학습
-분류(Classification)
-특성(Feature)
-예측 변수(Predictor Vaiable)
-회귀(Regression)
지도학습 알고리즘
- k-최근접 이웃(K-Nearest Neighbors)
-선형 회귀(Linear Regression)
-로지스틱 회귀(Logistic Regression)
-서포트 벡터 머신(Support Vector Machine, SVM)
-결정 트리(Decision Tree)
-랜덤포레스트(Random Forest)
-신경망(Neural Networks)
지도 학습(Supervised learning) : 정답 데이터로 가르치는 것 (레이블링=라벨링이 필요함)
ex) 사과 데이터 보여주면서 이건 사과다. 강아지 데이터 보여주면서 이건 강아지다
분류(Classification) : 유사한 특성을 가진 데이터들끼리 묶어서 나누는 것
훈련 데이터(Training data) : [입력(input) - 데이터 + 타깃(target) - 정답]
이진 분류(Binary classification) : 두 가지를 구분할 수 있는 분류(데이터의 성질이 2가지 답으로 나타남)
EX) 병원에서 찍은 환자의 폐 CT 사진이 암인지 아닌지, 스팸 메일인지 아닌지 등
다중 분류( Multiclass classification) : 여러 개 중 하나 구별해 내는 분류 (데이터의 성질이 3가지 이상 답으로 나타난다)
EX) 새의 종류, 지폐의 종류 등
나이브 베이즈 분류(Naive Bayes Classification) : 베이즈 정리를 활용하여 판단하고 조건부 확률 모델이며, 모든 특성 값은 서로 독립이라고 가정
의사결정 트리(Decision Tree) : 관측값과 목표값을 연결하는 예측 모델
SVM(Support Vector Machine) : 데이터를 2개의 영역으로 분류하는 이진 분류기
k-최근접 이웃 알고리즘(K-Nearest neighbors) : 가장 가까운 이웃 샘플을 찾고 이 샘플들의 타깃 값을 평균하여 예측

회귀(Regression) : 연속적인 값을 예측하는 것
ex) 주식 예측, 성적 예측, 집값 예측, 물건 예측 등
선형 회귀(Linear regression) : 데이터를 가장 잘 설명하고, 예측하는 선을 찾는 것
단순 선형 회귀(Simple Linear regression) : 하나의 x값만으로도 y값을 설명할 수 있음
다중 선형 회귀(Multiple Linear regression) : y를 설명하는데, 여러 개의 x값이 필요할 때
독립변수(Independent variable) : 연구자가 의도적으로 변화시키는 변수
종속변수(Dependent variable) : 연구자가 독립변수의 변화에 따라 어떻게 변하는지 알고 싶어 하는 변수
로지스틱 회귀(Logistic regression) : 독립변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는 데 사용

최소 제곱법(Method of least squares) : 자료들 사이에 패턴을 도출하는 데 사용(아주 직관적이고 간단)

평균 제곱 오차(Mean square error) : 오차의 제곱에 대한 평균을 취한 값
(머신러닝 뿐만 아니라 영상처리 영역에서도 자주 사용되는 추측 값에 대한 정확성 측정 방법)

경사 하강법(Gradient descent) : 함수의 기울기(경사)를 구하고 경사의 절대값이 낮은 쪽으로 이동시켜서 극값에 이를 때까지 반복
※순간 기울기가 0인 즉 미분 값이 0인 지점 찾는 것
학습률(Learning rate) : 기울기의 부호를 바꿔 이동시킬 때 이동 거리를 정해주는 것
학습률이 너무 작은경우 : 학습시간이 오래 걸림, 지역 최솟값(local minimum)에 수렴
학습률이 너무 클경우 : 학습시간이 적게 걸리나 스텝(Step)이 너무 커 전역 최솟값(Global minimum)을 가로 질러 반대편으로 건너뛰어 최솟값에서 멀어질 수 있음

비지도학습
군집(Clustering)
-k-평균(K-Means)
-DBSCAN
-계층 군집 분석(Hierarchical Cluster Analysis, HCA)
-이상치 탐지(Outlier Detection)
-특이치 탐지(Novelty Detection)
-원클라스(One-Class SVM)
-아이솔레이션 포레스트(Isolation Forest)
시각화(Visualization) 와 차원축소(Dimensionality Reduction)
-주성분 분석(Principal Component Analysis)
-커널(Kernel PCA)
-지역적 선형 임베딩(Locally-Linear Embedding LLE)
-t-SNE(T-Distributed Stochastic Neighbor Embedding)
연관 규칙 학습
-어프라이어리(Association Rule Learning)
-이클렛(Eclat)
비지도 학습(unsupervised learning) : 정답이 없는 데이터를 사용해 가르치는 것 (레이블링=라벨링 X)
EX) 사람들의 특징을 구분할 때, 군집화(clustering), 차원 축소(dimensionality redution)
군집화(Clustering) : 데이터들의 여러 특징들을 보고, 특징들 뽑아내서 묶는 것
EX) 무언가 추천할 때, 넷플릭스 추천영화, 유튜브 추천 영상, 아마존 추천 상품
차원 축소(Dimensionality redution) : 차원 = 데이터 특징(feature)을 모두 고려할 수 없으니까 몇 가지 특징으로 줄임
EX) 집값 예측 과정 데이터 특징 : 방 개수, 범죄율, 교통 접근성, 가격, 주변 상가
차원 축소 -> 방개수, 범죄율, 가격
추천 시스템(Recommender System) : 추천을 위해 연관 데이터 정의에 도움 주는 클러스터링 방법
K-meas 클러스터링 : 유사한 특성을 가진 K개의 데이터 그룹으로 묶는 방법
(비지도 학습 알고리즘 중 대표적인 클러스터링 방법)
| K-means 클러스터링 활용 분야 | 통계 | 주어진 데이터의 분류나 성향 분석 |
| 전자상거래 | 고객의 구매 이력으로 고객 분류 | |
| 건강 관리 | 질병과 치료를 위한 패턴 탐지 | |
| 패턴 | 유사한 이미지를 그룹화 | |
| 재무 | 신용카드 사기 탐지 | |
| 회사 | 매출 등을 토대로 회사의 등급 분류 | |
| 기술 | 네트워크 침입과 악의적 활동 탐지 | |
| 기상예보 | 폭풍 예측 |
※지도 학습과 비지도 학습의 특징 비교
| 지도 학습 | 비지도 학습 | |
| 입력 데이터 | 입력과 출력값또는 레이블이 지정된 데이터를 사용해 학습함 | 출력값이나 레이블이 전혀 없는 데이터를 사용하여 학습함 |
| 주요 기능 | 분류, 회귀 | 클러스터링, 추천 시스템 |
| 계산의 복잡성 | 비교적 간단함 | 상당히 복잡함 |
| 정확성 | 매우 정확함 | 다소 덜 정확함 |

강화 학습 (Reinforcement learning) : 목표를 달성하기 위해서 인공지능 스스로 자신에게 상을 주며 목표를 이루어 감
EX) 아타리(Atari) 벽돌 깨기, 딥마인드(DeepMind), 체스와 알파고 등
베이즈의 정리(Bayesian theorem) : 두 확률 변수의 확률과 사후 확률 사이의 관계를 나타내는 정리
(과거의 데이터들을 기반으로 미래를 예측하는 모델)
EX) 검색 엔진, 스팸 메일 차단, 금융 이론, 승부 예측, 기상 예측, 의료 분야 등 사용
베이즈 네트워크(Bayesian network) : 집합을 조건부 독립으로 표현하는 확률의 그래픽 모델
은닉 마르코프 모델(Hidden Markov Model, HMM) : 은닉된 상태와 관찰 가능한 결과로 이루어진 확률형 모델
(대량의 데이터를 통계적으로 분석하여 추론에 응용)
EX) 음성인식, 자연어 처리 등에 활용

인공 신경망(ANN, Artificial Neural Network) : 신경망을 사람들이 인공적으로 만든 것
인공 신경망에서는 신경망의 최소 구성단위인 뉴런이 다른 뉴런과 연결된 모습을 각각의 층,
레이어라는 개념을 사용함. 입력 레이어(input layer), 히든 레이어(hidden layer) , 출력 레이어로 구성(output layer)
입력층(Input layer) : 데이터를 입력받는 층 /머신러닝에서 말하는 feature(속성)
EX) 사람으로 치면 키, 몸무게, 나이
은닉층(Hidden layer) : 입력층에서 들어온 데이터가 여러 신호로 바뀌어서 출력층까지 전달됨 이때 연결된 여러 뉴런을 지날 때마다 신호 세기가 변경됨
출력층(Output layer) : 이 출력층에 어떠한 값이 전달되었냐에 따라 인공지능의 예측 값이 결정됨
전방 전달(feed-forward) : 입력층(Input layer) ->은닉층(Hidden layer) ->출력층(Output layer)으로 입력값을 계산하여 예측값을 계산하는 과정
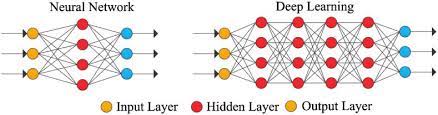
심층 신경망(DNN, Deep Neural Network), 딥러닝(Deep Learning) : 입력층과 출력층 사이에 여러 개의 은닉(Hidden layer)들로 이뤄진 인공신경망을 딥 뉴럴 네트워크(Deep Neural NEtwork) 또는 딥러닝(Deep Learning)이라고
| 서비스 유형 | 딥러닝 모형(주로 사용되는 알고리즘) |
| 이미지 판별, 객체인식, 얼굴인식 | CNN(VGG, ResNet, GoogleNet, Inception, R-CNN, YOLO) |
| 챗봇, 음성스피커, 기계번역 | RNN, LSTM, Seq2Seq, Attention, BERT |
| 이미지 합성, 이미지 생성, 화자 판별 | Neural Style Transfer, GAN, DCGAN |
| 자율주행 | CNN계열을 통한 동적/정적 객체 인식, 강화학습을 통한 움직임 정의 |
특성(Feature) : 데이터를 표현하는 하나의 성질
EX) 남녀 추론할 때에 키, 머리카락 길이, 얼굴 길이, 성별 등 데이터를 특성이라고 함
훈련(Train) : 머신러닝 알고리즘이 데이터에서 규칙을 찾는 과정
모델(Model) : 알고리즘이 구현된 객체
결정계수(R**2) : 대표적인 회귀 문제의 성능 측정 도구, 에 가까울수록 좋고, 0에 가깝다면 성능이 나쁜 모델
정확도(Accuracy) : 정확도 = (정확히 맞춘 개수/ 전체 데이터 개수)
훈련 세트(Train set) : 모델을 훈련할 때 사용하는 데이터
테스트 세트(Test set) : 모델을 평가할 때 사용하는 데이터
데이터 전처리(Data preprocessing) : 머신러닝 모델에 훈련 데이터를 주입하기 전에 가공하는 단계
표준점수(Standard score) : 훈련 세트의 스케일을 바꾸는 대표적인 방법 중 하나, 특성의 평균을 빼고 표준편차로 나눔
파라미터(Parameter) : 모델 내부에서 결정하는 변수 (데이터로부터 결정됨)
모델 파라미터(Model parameter) : 머신러닝 모델이 특성에서 학습한 파라미터
하이퍼 파라미터(Hyper parameter) : 모델링할 때 사용자가 직접 세팅해주는 값
앙상블 : 하나의 모델로는 결과가 치우쳐질 수 있으니, 여러가지 모델로 학습하는것
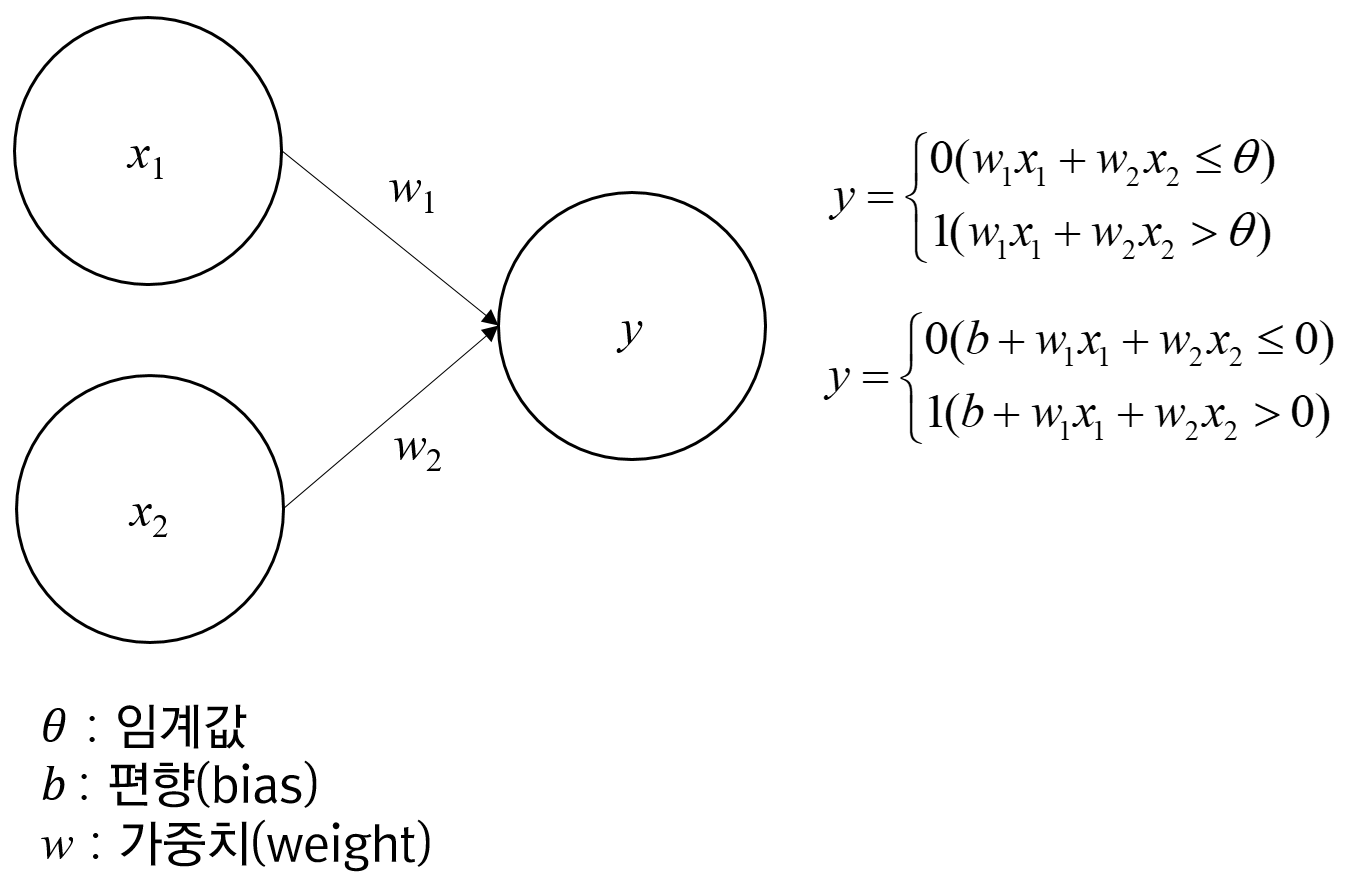
퍼셉트론(Perceptron) : 신경망(딥러닝)의 기원이 되는 알고리즘, 다수의 신호를 입력 받아 하나의 신호를 출력하는 알고리즘
※AND, NAND, OR 게이트 학습가능하나 XOR은 학습 불가능

다층 퍼셉트론(Multilayer Perceptron) : 은닉 층이 1개 이상인 퍼셉트론. 위 그림과 같이 은닉층이 2개 이상인 신경망을 심층 신경망(Deep Neural Network, DNN)이라고 한다. 학습을 시키는 신경망이 심층 신경망일 경우 심층 신경망을 학습시킨다고 하여 딥러닝(Deep Learning)이라고 함
※여러 겹의 층이 존재해서 선형 분류만으로 풀지 못했던 문제를 비선형적으로 해결 가능(XOR문제 해결 가능)
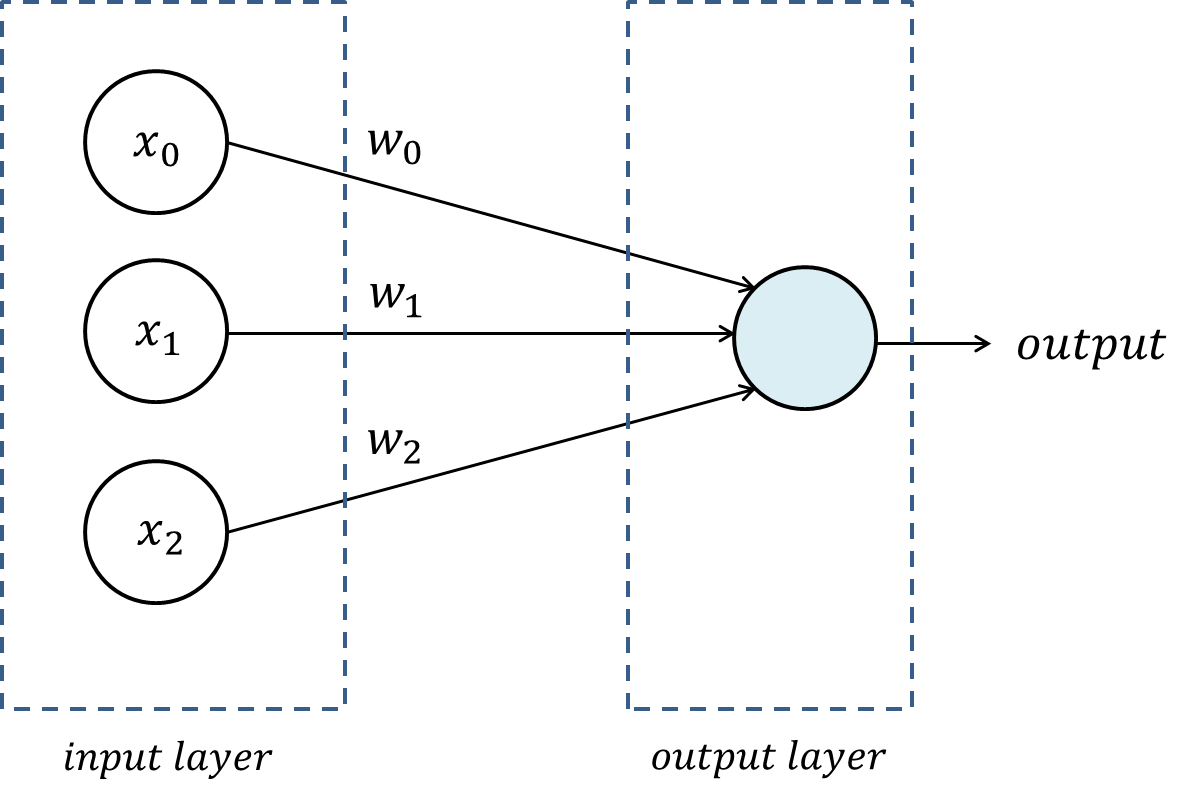
가중치(Weight) : 각 입력층(Input layer)에 대해 일정량의 중요도를 부여하는 개념 (가중치는 기울기와 절편을 의미하는 경우가 많음)
EX) 어떤 입력층(Input layer)에 대해 가중치(Weight)가 크다는 건 입력층(Input layer)이 출력층(Output layer)을 결정하는데 더 큰 역할을 한다는 뜻
편향(bias) : 인공 신경망에서 모델의 성능을 높이기 위해 가중치를 거쳐 변환된 신호 세기를 조절할 때, 한쪽으로 치우치는 값을 더할 때 편향이라는 값을 사용
(퍼셉트론이 얼마나 쉽게 활성화(Activation) 되는지를 조절하는 매개변수)
※※※가중치와 편향은 신호 세기를 변경하는 데 사용하는데 뒤쪽으로 전달되는 신호 세기는 앞쪽 뉴런에서 전달된 신호의 값에 가중치라는 값을 곱하고, 편향을 더해서 다음으로 전달합니다.
그래서 인공신경망이 학습한다는 의미는 가중치와 편향 값을 각 데이터에 맞게끔 정교하게 맞추어 간다는 의미입니다.
인공신경망의 층이 깊어질수록 가중치 값은 그에 비례해서 많아지는데 각각의 값을 최적화할 때에는 컴퓨터의 성능이 중요한 역할을 담당하게 됩니다. 여기에 설명한 거처럼 인공신경망의 기초 개념이 가중치와 편향이라는 걸 알 수 있는데 그만큼 중요한 개념입니다.
역치(Action potiential) : 특정한 신호가 어떤 값(역치) 이상 전달되었을 경우에는 다음 뉴런으로 신호를 전달하지만 어떤 값(역치) 보다 작을 경우에는 전달하지 않음
(뉴런으로 들어오는 여러 신호를 조절)
※활성화 함수(activation function)와 같은 개념
※뉴런에서 다른 뉴런으로 신호를 전달하고, 전달받을 때에는 가중치, 역치, 활성화 함수의 개념 사용
활성화 함수(Activation function) : 입력 신호의 총합을 출력 신호로 변환하는 함수

이항 교차 엔트로피(Binary crossentropy) : 인공 지능이 잘 예측하면 오차값 0으로 주고, 잘 예측하지 못한다면 오차값이 상당히 커짐
다중 분류 손실 함수(Categorical crossentropy) : 여러 값 중 하나를 예측하는 모델일 경우 정답을 예측할 경우에는 오차를 0으로, 정답이 아닌 값을 높은 확률로 예측하면 오차를 많게, 낮은 확률로 정답이 아닌 확률을 예측하면 오차를 적게 하는 방법
평균 제곱 오차(Mean squared error) : 예측 값이 실제 값에서 얼마나 떨어져 있는지 알아보는 방법
오차를 제곱하기 때문에 평균 제곱 오차라 고함. 제곱하는 이유는 바로 부호를 없애기 위해서 인데,
얼마나 떨어져 있는지 양의 방향인지 음의 방향인지는 중요하지 않기 때문이다.
오차 역전파(back-propagation): 알고리즘은 역순으로 출력 값과 예측값의 오차가 줄어드는 방향으로 각각의 가중치를 조정하는 과정

import: 만들어둔 파이썬 패키지(함수 묶음)를 불러오는 명령어
Epoch : 전체 훈련 데이터에 대한 훈련 횟수
loss : 손실, 비용 (값이 낮을수록 학습이 잘된 것)
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=2, activation='sigmoid', input_shape=(2,)),
tf.keras.layers.Dense(units=1, activation='sigmoid')
])
Dense : 레이어의 입력과 출력 사이에 있는 모든 뉴런이 서로 연결되는 레이어
units : 레이어를 구성하는 뉴런의 수를 정의함
(뉴런이 많을수록 일반적으로 레이어 성능이 좋아지지만 계산량이 많아지고, 메모리도 많이 차지함)
activation : Units에서 다음 신호로 보낼지 판별하는 함수
(뉴련에서 계산된 값이 임계치를 넘는지 여부와 이를 토대로 다음 신호 전달 여부를 활성할 것인지 판단)
input_shape : 시퀀셜 모델의 첫 번째 레이어에서만 정의하는데, 입력의 차원 수가 어떻게 되는지를 정의
(2개의 입력을 받는 1차원 array이기 때문에 1차원의 원소의 개수인 2를 명시해서 (2,)이라고 정의)
model.compile(loss = 'mean_squared_error', optimizer = 'adam', metrics=['accuracy'])
model.fit(X, Y, epochs = 100, batch_size = 10)optimizer : 오차를 어떻게 줄여 나갈지 정하는 함수

과적합(Overfitting) : 훈련 데이터를 과하게 학습한 경우
(훈련 세트 성능이 테스트 세트 성능보다 훨씬 높을 때 일어남,
훈련 세트에 너무 집착해서 데이터에 내재된 거시적인 패턴을 감지 못함)
※훈련 데이터에서는 오차가 낮지만, 테스트 데이터에 대해서는 오차가 높아지는 상황 발생
과소 적합(Underfitting) : 훈련 자체가 부족한 상태이므로 훈련 데이터에 대해서도 보통 정확도가 낮음
(훈련 세트와 테스트 세트 성능이 모두 동일하게 낮거나 테스트 세트 성능이 오히려 더 높을 때 일어남,
이런 경우 더 복잡한 모델을 사용해 훈련 세트에 잘 맞는 모델을 만들어야 함)
scatter plot(산점도) : x, y축으로 이뤄진 좌표계에 두 변수(x, y)의 관계를 표현하는 방법
드롭아웃(Dropout) : 은닉층에 있는 뉴런의 출력을 랜덤 하게 꺼서 과대 적합을 막는 기법.
※드롭아웃은 훈련 중에 적용되며 평가나 예측에서는 적용하지 않음(텐서 플로는 이를 자동으로 처리함)
콜백(Callback) : 케라스 모델을 훈련하는 도중에 어떤 작업을 수행할 수 있도록 도와주는 도구
※대표적으로 최상의 모델을 자동으로 저장해주거나 검증 점수가 더 이상 향상되지 않으면 일찍 종료
조기종료(Early stopping) : 검증 점수가 더 이상 감소하지 않고 상승하여 과대 적합이 일어나면 훈련을 계속 진행하지 않고 멈춤(계산 비용과 시간을 절약함)
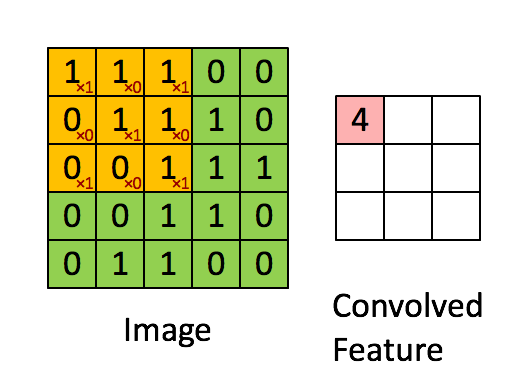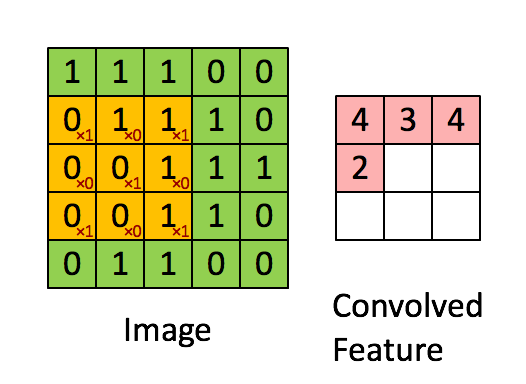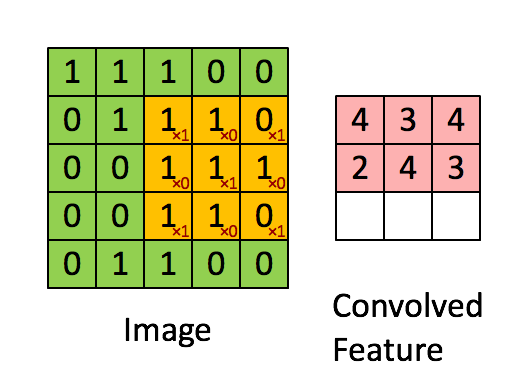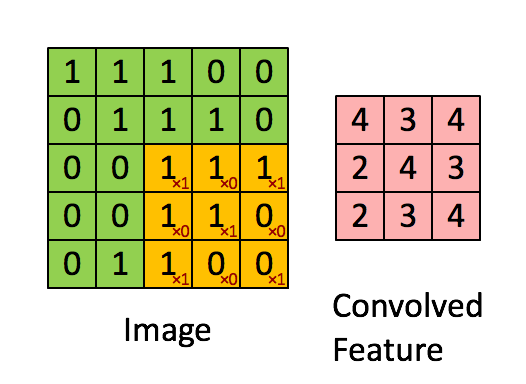
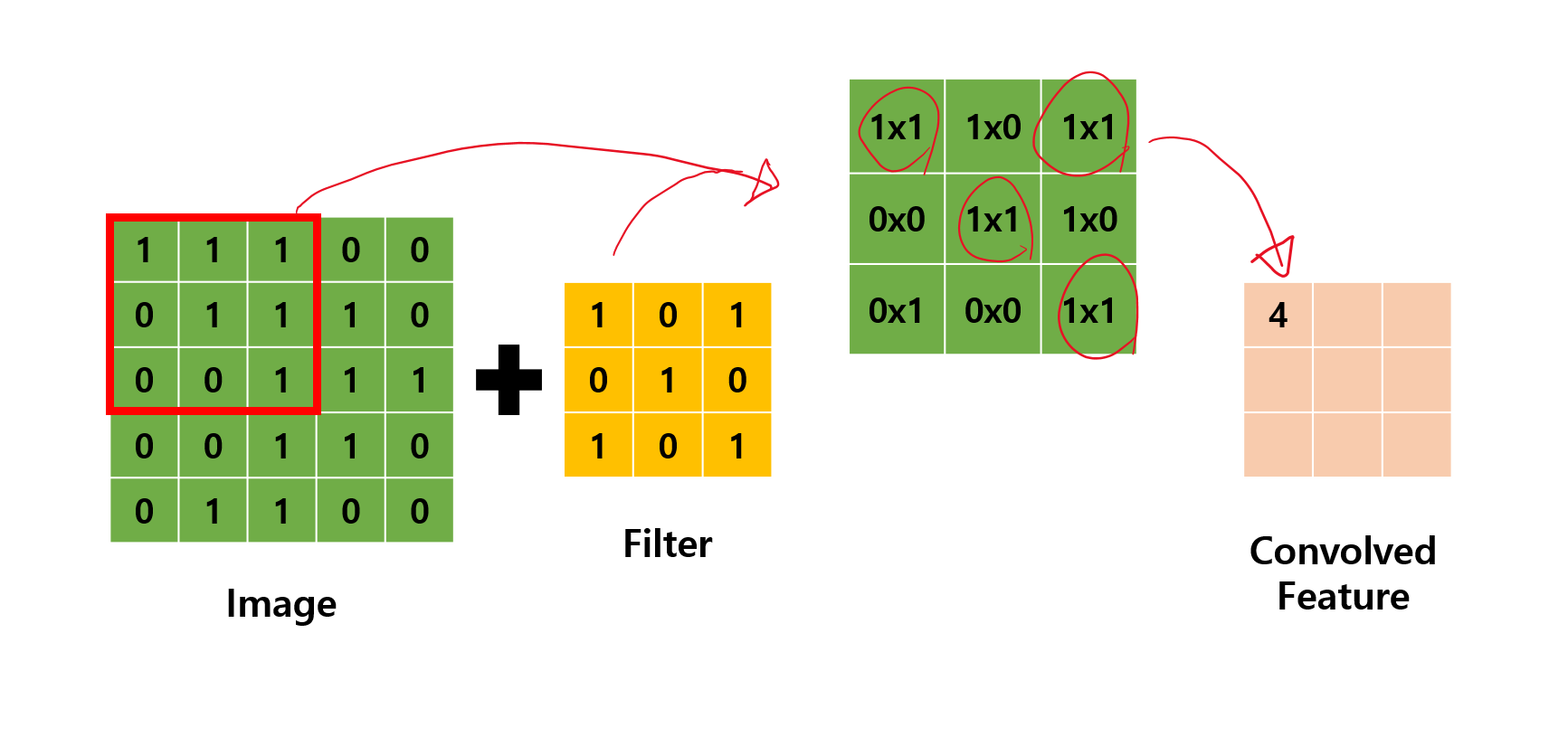
CNN에서는 입력 위를 이동하면서 출력을 만들기 때문에 뉴런(Neural) -> 필터(Filter) or 커널(Kernel)이라고 부름
합성곱(Convolution) : 밀집층과 비슷하게 입력과 가중치를 곱하고 절편을 더하는 선형 계산
특성 맵(Feature map) : 합성곱 층이나 풀링 층의 출력 배열을 의미함
※합성곱 층에서 5개의 필터를 적용하면 5개의 특성 맵이 만들어짐
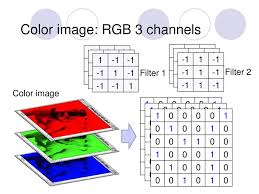
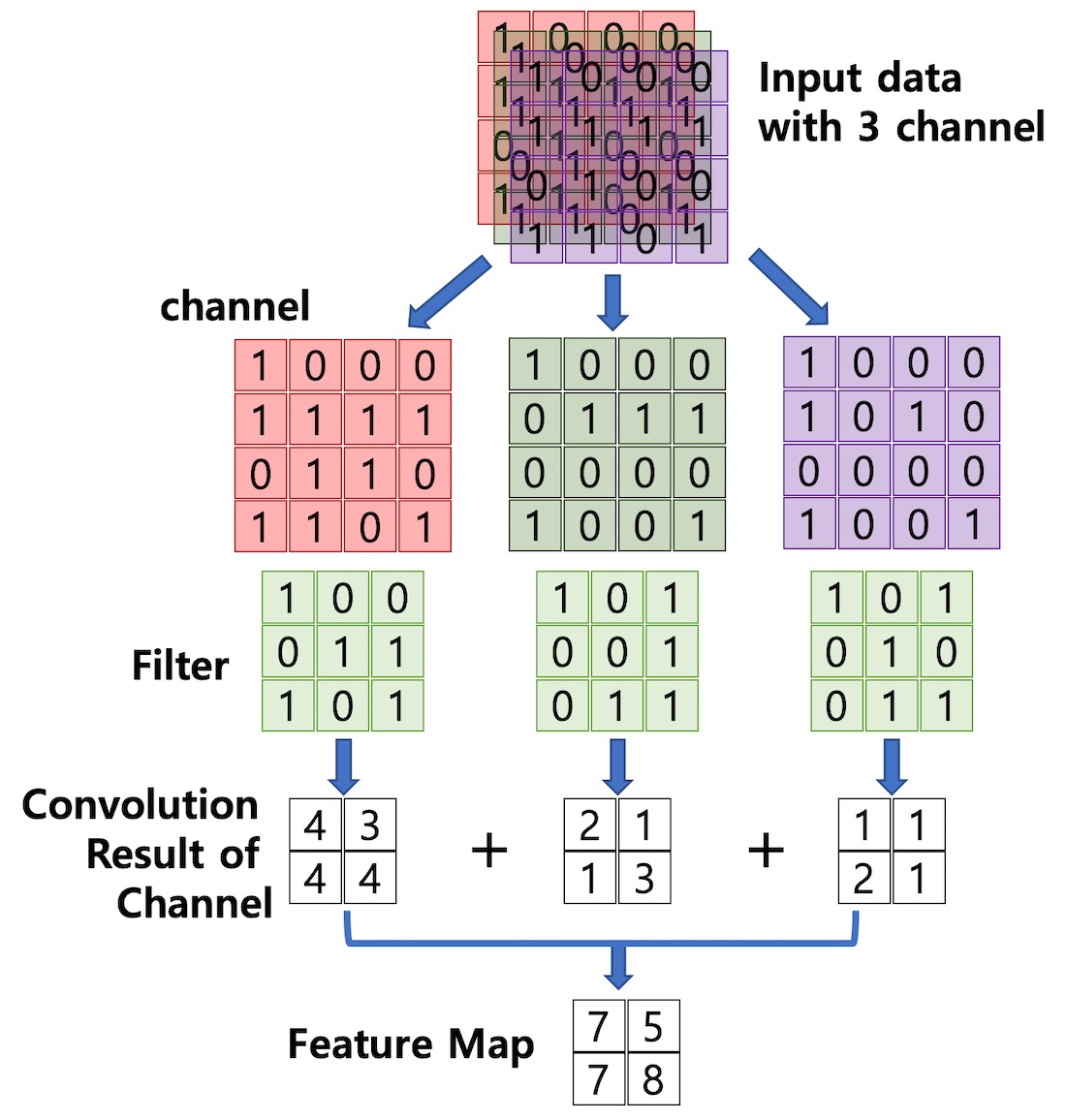
채널(Channel) : 컬러 이미지는 RGB채널(3개)로 구성되어 있음.
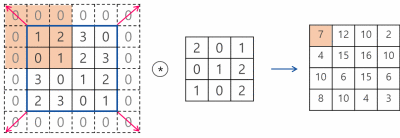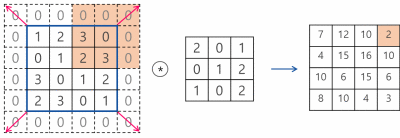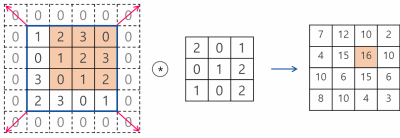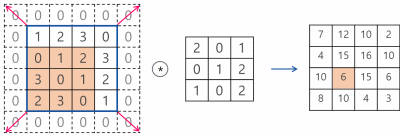
스트라이드(Stride) : 몇 칸씩 이동하며 합성곱을 계산
패딩(Padding) : 합성곱 층의 입력 주위에 추가한 0으로 채워진 픽셀 (입력 데이터보다 출력 데이터가 작아지는 것을 방지)
※0으로 둘러싸는 패딩(Padding)을 제로 패딩(Zero padding)이라고 함
세임 패딩(Same padding) : 입력과 특성 맵의 크기를 동일하게 만들기 위해 입력 주위에 0으로 패딩 하는 것
※입력 데이터와 출력 데이터가 같음
밸리드 패딩(Valid padding) : 패딩 없이 순수한 입력 배열에서만 합성곱을 하여 특성 맵을 만드는 경우
※입력 데이터보다 출력 데이터의 크기가 작음
Conv2 D : 입력의 너비와 높이 방향의 합성곱 연산을 구현한 클래스
MaxPooling2 D : 입력의 너비와 높이를 줄이는 풀링 연산을 구현한 클래스
함수형 API(functional API) : 복잡한 모델을 만들 때 Sequential 클래스를 사용하기 힘들 때 함수형 API를 사용
※케라스에서 신경망 모델 만드는 방법 중 하나 Model클래스에 모델의 입력, 출력을 지정. 전형적으로 입력은 Input() 함수를 사용하여 정의 출력은 마지막 층의 출력으로 정의

오토 인코더(AutoEncoder) : 입력 데이터를 출력 데이터로 재생성하는 신경망
- 비지도 학습 (Unsupervised) 방식의 인공 신경망
- 손실 압축으로 입력 데이터와 출력 데이터는 완전히 일치하지 않음
- 비손실 압축보다 압축률이 훨씬 좋음
- 압축된 특징을 잠재 변수(Latent vector)이라고 함
- 잠재 변수는 데이터의 특징을 가장 잘 표현하는 정보이기 때문에 여러 가지 용도로 쓰임
인코더(Encoder) : 고차원 정보를 압축함
디코더(Decoder) : 압축된 고차원 정보를 다시 원래 상태로 만듦
순차 데이터(Sequential Data)) : 텍스트나 시계열 데이터와 같이 순서에 의미가 있는 데이터
ex) 글, 대화, 일자별 날씨, 일자별 판매 실적 등

순환 신경망(Recurrent Neural Network, RNN) : 순차 데이터에 잘맞는 인공 신경망의 종류, 순차 데이터를 처리하기 위해 고안된 순환층을 1개 이상 사용한 신경망
자연어 처리(Natural Language Processing, NLP) : 컴퓨터를 사용해 인간의 언어를 처리하는 분야. 대표적인 세부 분야로는 음성 인식, 기계 번역, 감성 분석 등이 있음.
토큰(Token) : 텍스트에서 공백으로 구분되는 문자열
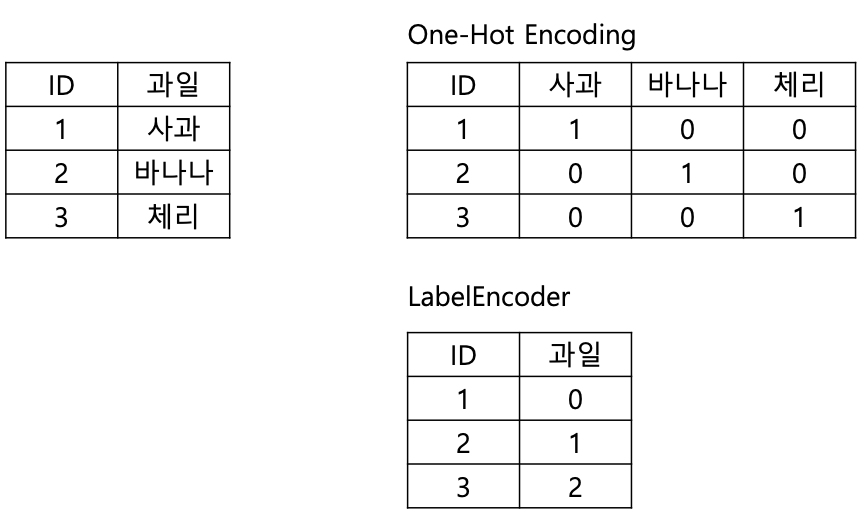
원-핫 인코딩(One-Hot Encoding) : 어떤 클래스에 해당하는 원소만 1이고 나머지는 모두 0인 벡터
단어 임베딩(Word Embedding) : 정수로 변환된 토큰을 비교적 작은 크기의 실수 밀집 벡터로 변환. 이런 밀집 벡터는 단어 사이의 관계를 표현할 수 있기 때문에 자연어 처리에서 좋은 성능을 발휘
LSTM(Long Short-Term Memory) : 단기 기억을 오래 기억하기 위해서 고안
Reperence : 혼자 공부하는 머신러닝 + 딥러닝, 모두의 인공지능 with 파이썬, 모두의 딥러닝, Hands-On Machine Learning with Scikit-Learn, Keras&TensorFlow 2판
'인공지능 관련' 카테고리의 다른 글
| sigmoid함수 시각화 (0) | 2021.04.29 |
|---|---|
| 파이썬 인공지능 관련 함수 (0) | 2021.04.29 |
| 딥러닝 코드 분석 (0) | 2021.04.28 |
| Numpy 함수들 (0) | 2021.04.28 |
| 주피터 노트북 ModuleNotFoundError: No module named 'tensorflow' 에러 해결법 (0) | 2021.04.28 |